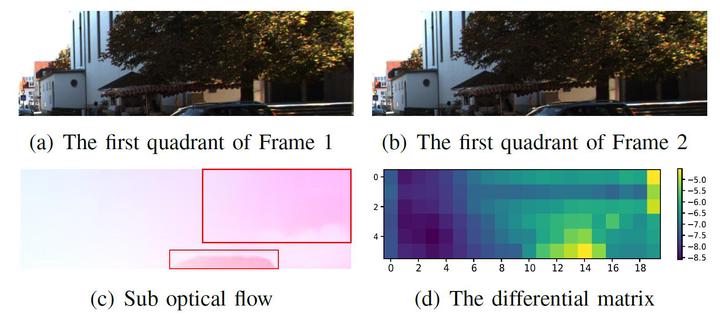
 Performance of attention mechanism (CBAM)
Performance of attention mechanism (CBAM)
Background
Visual Odometry (VO), recovers the ego-motion from image sequences by exploiting the consistency between consecutive frames, which has been widely applied to various applications, ranging from autonomous driving and space exploration to virtual and augmented reality. Although many state-of-the-art learning-based methods have yielded competitive results against classic algorithms, they consider the visual cues in the whole image equally.
Contribution
The proposed DeepAVO distinguishes and selects extracted features from two aspects: 1) there are four branches extract geometric information from corresponding quadrant of optical flow; 2) each branch in the DeepAVO contains two CBAM blocks enabling the model to concentrate on pixels in distinct motion. The contributions can be summarized into:
- Novel visual perception guiding ego-motion estimation: The DeepAVO considers the features in four quadrants of optical flow dividually, and fuse the distilling module into each encoder branch. It makes the learning-based model pays more attention to the visual cues that are effective for ego-motion estimation.
- Accurate and robust VO: Our medel outperforms many learning-based and traditional monocular VO methods, and even gives competitive results against the classic stereo VISO2-S algorithm. In addation, the DeepAVO produces promising tracking results on the cross-dataset validation.